{kind=link}
RAG ve Bileşenleri
RAG (Retrieval-Augmented Generation), büyük dil modellerinin hafızasını genişleten bir teknoloji. Düşünün ki, bir öğrencinin sınava girerken yanında ansiklopedi götürmesine benziyor. Model, soruyu yanıtlamadan önce güvenilir kaynaklardan bilgi topluyor.
Temel bileşenler:
- Veri Tabanı: Şirketinizin tüm dokümanları, PDF’ler, web sayfaları burada saklanır
- Embedding Modeli: Metinleri matematiksel vektörlere çevirir (kelimeler arası benzerliği anlar)
- Vektör Veritabanı: Bu matematiksel temsilleri saklar ve hızlıca arama yapar
- Retriever: Soruyla en alakalı bilgi parçalarını bulur
- LLM: Bulunan bilgileri kullanarak cevap üretir
Kullanım örneği: Bir müşteri hizmetleri chatbotu, şirketin tüm ürün katalogunu RAG ile tarayarak müşteriye doğru bilgi verebilir.
RAG Mimari Varyantları
RAG sistemleri farklı ihtiyaçlara göre çeşitli şekillerde kurulabilir:
Naive RAG: En basit hali. Soru gelir → ilgili dokümanlar bulunur → cevap üretilir. Hızlıdır ama bazen alakasız bilgiler getirebilir.
Advanced RAG: Daha akıllı. Soruyu önce yeniden yazabilir, birden fazla arama yapabilir. Mesela “Bu nasıl çalışır?” sorusunu “X ürününün çalışma prensibi nedir?” şeklinde detaylandırabilir.
Modular RAG: Lego gibi. İhtiyaca göre modüller eklenip çıkarılabilir. Bir modül çeviri yaparken, diğeri özetleme yapabilir.
Hybrid Search RAG: Hem anahtar kelime hem de anlamsal arama yapar. “iPhone 15” ararken hem bu kelimeleri hem de “Apple’ın son telefonu” gibi anlamsal benzer ifadeleri bulur.
RAG sistemini bir kütüphane gibi düşünelim. Nasıl ki kütüphanede kitap bulmak için katalog, raf sistemi ve kütüphaneci gerekiyorsa, RAG’da da benzer bileşenler var. Her birini detaylıca inceleyelim:
Doküman Yükleme ve İşleme (Document Ingestion)
Bu aşama, kütüphaneye yeni kitapların gelmesi gibidir. Sistemimize bilgi kaynaklarını ekliyoruz.
Desteklenen formatlar:
- PDF, Word, Excel dosyaları
- Web sayfaları (HTML)
- Veritabanları (SQL, NoSQL)
- API’lerden gelen veriler
- Görüntüler (OCR ile metin çıkarma)
Örnek senaryo: Bir şirketin 10 yıllık teknik dokümanları, müşteri e-postaları ve ürün katalogları sisteme yükleniyor. Her biri farklı formatta olabilir ama hepsi işlenip kullanılabilir hale getiriliyor.
Chunking (Parçalama)
100 sayfalık bir kitabı ezberlemek zor, ama paragraf paragraf öğrenmek kolaydır. Chunking de tam olarak bunu yapar.
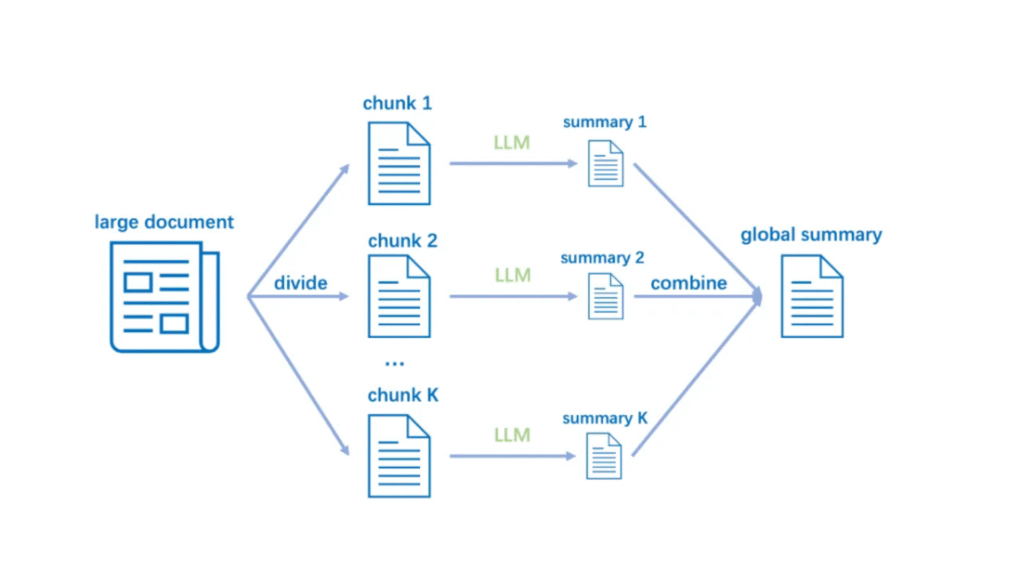
Neden gerekli?
- LLM’lerin context (bağlam) limiti var (örneğin 4000 kelime)
- Küçük parçalar daha hızlı işlenir
- Alakalı bilgi daha kolay bulunur
Chunking stratejileri:
Sabit boyut: Her 500 kelimede bir böl
Örnek: "Ürünümüz 2010 yılında piyasaya sürüldü. Özellikle
genç kullanıcılar arasında popüler oldu..." [500 kelime]
---yeni chunk---
"Teknik özelliklere bakıldığında, cihaz 5 inç ekrana sahip..." [500 kelime]Cümle bazlı: Anlamlı cümle grupları
Chunk 1: "Ürün özellikleri: Hızlı işlemci. Uzun batarya ömrü.
Hafif tasarım."
Chunk 2: "Fiyatlandırma: Standart paket 1000 TL. Premium paket 1500 TL."Semantik chunking: Anlama göre bölme
- Konu değiştiğinde yeni chunk başlar
- Daha akıllı ama daha yavaş
Overlap (Örtüşme): Chunklar arası bağlamı korumak için
Chunk 1: "...batarya 10 saat dayanır. Hızlı şarj özelliği vardır."
Chunk 2: "Hızlı şarj özelliği vardır. 30 dakikada %80 dolar..."Embedding Model
Embedding, kelimeleri sayılara çeviren sihirli değnek gibidir. “Kedi” kelimesini [0.2, 0.8, 0.1, …] gibi bir sayı dizisine çevirir.
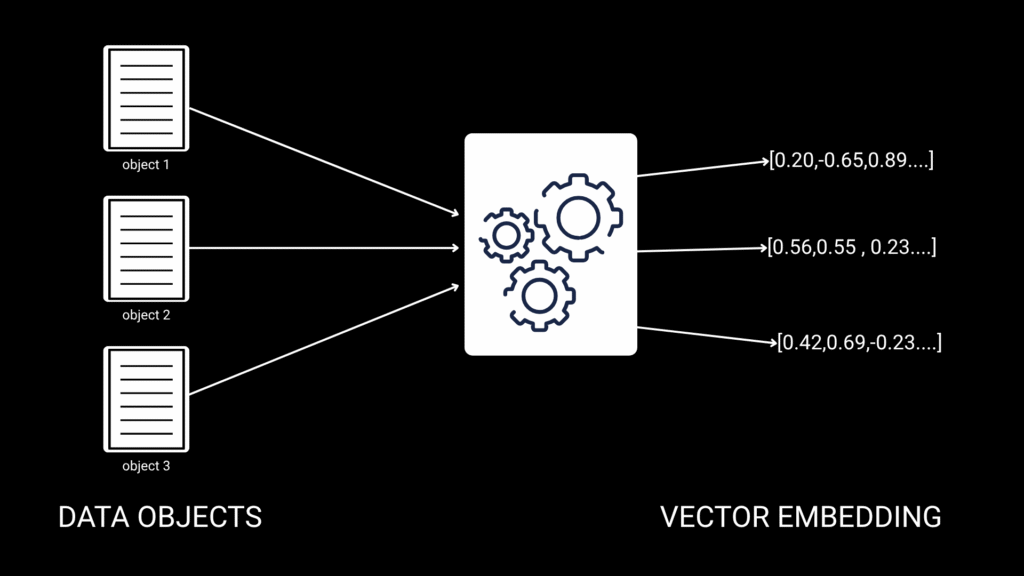
Nasıl çalışır? Her kelime veya cümle, çok boyutlu uzayda bir nokta olur. Benzer anlamlar yakın noktalarda bulunur.
"Köpek" → [0.2, 0.9, 0.1, 0.3, ...]
"Kedi" → [0.2, 0.8, 0.1, 0.4, ...]
"Araba" → [0.9, 0.1, 0.7, 0.2, ...]Köpek ve kedi vektörleri birbirine yakın (ikisi de evcil hayvan), araba ise uzak.
Popüler Embedding Modelleri:
- OpenAI Ada-002: 1536 boyutlu, genel amaçlı
- Sentence-BERT: Açık kaynak, 768 boyutlu
- E5-large: Çok dilli destek
- BGE modelleri: Türkçe için optimize
Örnek kullanım:
python
# Pseudo-kod
metin = "Müşteri iadesi nasıl yapılır?"
embedding = model.encode(metin)
# Sonuç: [0.23, -0.45, 0.67, ...] (1536 sayı)Vektör Veritabanı (Vector Database)
Vektör veritabanı, embedding’leri saklayan ve süper hızlı arayan özel bir depo. Normal veritabanları “tam eşleşme” ararken, vektör veritabanları “benzerlik” arar.
Nasıl Çalışır?
Geleneksel veritabanı araması:
sql
SELECT * FROM dokuman WHERE baslik = "İade Politikası"
-- Sadece tam eşleşmeleri bulurVektör veritabanı araması:
Soru: "Ürünü geri vermek istiyorum"
Bulur:
- "İade Politikası" (benzerlik: 0.95)
- "Ürün değiştirme prosedürü" (benzerlik: 0.87)
- "Müşteri hakları" (benzerlik: 0.76)Benzerlik Hesaplama Yöntemleri:
Cosine Similarity (Kosinüs Benzerliği): İki vektör arasındaki açıyı ölçer. 1’e yakın = çok benzer, 0 = alakasız
"kedi" ve "köpek" arasında: 0.85 (yüksek benzerlik)
"kedi" ve "yazılım" arasında: 0.12 (düşük benzerlik)Euclidean Distance (Öklid Mesafesi): Düz çizgi mesafesi. Daha küçük = daha benzer
Dot Product (Nokta Çarpımı): Hızlı hesaplama için optimize
Popüler Vektör Veritabanları:
Pinecone
- Bulut tabanlı, kolay kullanım
- Otomatik ölçeklendirme
- Fiyat: Ayda $70’dan başlıyor
- Örnek: Spotify müzik önerileri için kullanıyor
Weaviate
- Açık kaynak
- GraphQL desteği
- Hibrit arama (vektör + anahtar kelime)
- Örnek: Bir e-ticaret sitesi ürün araması
Chroma
- Basit, Python-friendly
- Küçük projeler için ideal
- Lokal çalışabilir
- Örnek: Prototip chatbot’lar
Qdrant
- Rust ile yazılmış, çok hızlı
- On-premise kurulum için ideal
- Filtreleme özellikleri güçlü
Milvus
- Büyük ölçek için optimize
- Milyarlarca vektör saklayabilir
- Örnek: Alibaba’nın görsel arama sistemi
FAISS (Facebook AI)
- Kütüphane, tam veritabanı değil
- Çok hızlı, araştırma için popüler
- GPU desteği
Vektör Veritabanı Örnek Senaryo:
python
# Bir müşteri destek sistemi örneği
# 1. Dokuman ekleme
dokuman = "İade işlemi 14 gün içinde yapılabilir"
embedding = embed_model.encode(dokuman)
vector_db.insert(
id="doc_001",
vector=embedding,
metadata={
"text": dokuman,
"kategori": "iade",
"tarih": "2024-01-15"
}
)
# 2. Sorgulama
soru = "Ürünü ne zamana kadar geri verebilirim?"
soru_embedding = embed_model.encode(soru)
# 3. En benzer 3 dokümanı bul
sonuclar = vector_db.search(
vector=soru_embedding,
top_k=3,
filter={"kategori": "iade"} # Opsiyonel filtreleme
)
# Sonuçlar benzerlik skoruyla gelir:
# 1. "İade işlemi 14 gün içinde..." (skor: 0.92)
# 2. "Değişim süresi 30 gündür..." (skor: 0.76)
# 3. "Hasarlı ürünler için..." (skor: 0.65)Retriever (Geri Getirici)
Retriever, kütüphanedeki araştırmacı gibidir. Sorunuza en uygun bilgi parçalarını bulup getirir.
Retriever Tipleri:
Dense Retriever: Sadece vektör benzerliği kullanır
- Avantaj: Anlamsal arama yapar
- Dezavantaj: Özel isimler, kodlar için zayıf
Sparse Retriever: Anahtar kelime tabanlı (BM25 gibi)
- Avantaj: Kesin terimler için mükemmel
- Dezavantaj: Eş anlamlıları bulamaz
Hybrid Retriever: İkisinin kombinasyonu
Soru: "iPhone 15 özellikleri"
Dense: Anlamsal olarak telefon özelliklerini bulur
Sparse: "iPhone 15" kelimelerini tam bulur
Sonuç: İkisinin en iyi sonuçları birleştirilirRe-ranking: Bulunan sonuçları yeniden sıralama
İlk sonuçlar:
1. Genel telefon özellikleri (skor: 0.7)
2. iPhone 15 fiyatı (skor: 0.75)
3. iPhone 15 teknik özellikler (skor: 0.72)
Re-ranking sonrası:
1. iPhone 15 teknik özellikler (skor: 0.95)
2. iPhone 15 fiyatı (skor: 0.80)
3. Genel telefon özellikleri (skor: 0.60)
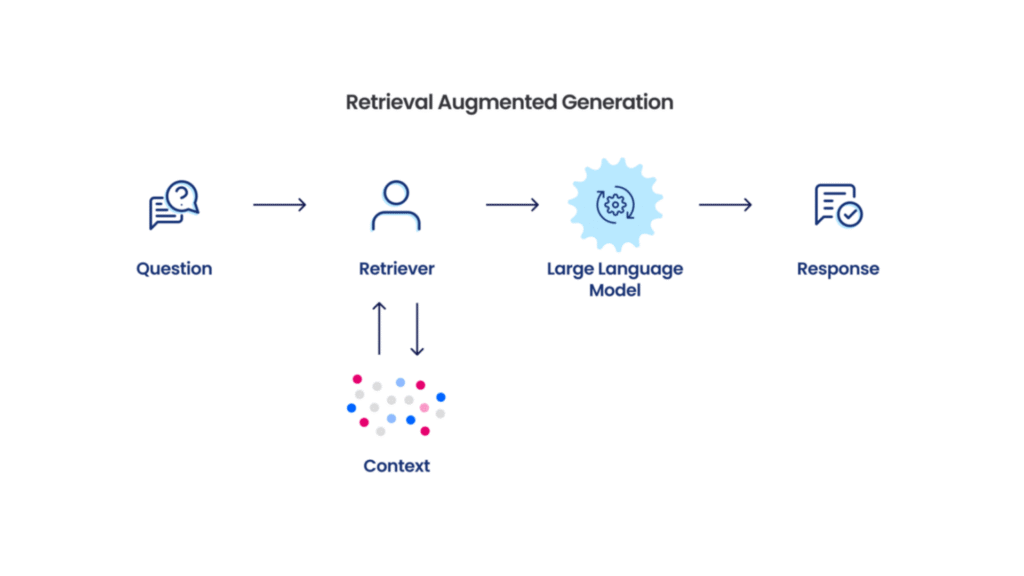
Context Builder (Bağlam Oluşturucu)
Retriever’ın bulduğu parçaları, LLM’in anlayabileceği şekilde düzenler.
Görevleri:
- Chunk’ları sıralama
- Gereksiz tekrarları temizleme
- Prompt’a ekleme
- Token limitini kontrol
Örnek:
Bulunan chunklar:
1. "Ürün garantisi 2 yıldır."
2. "Garanti kapsamı: Üretim hataları..."
3. "2 yıllık garanti süresince..."
Context Builder çıktısı:
"Bilgi: Ürün garantisi 2 yıldır ve üretim hatalarını kapsar.
Garanti süresince ücretsiz onarım yapılır."LLM (Large Language Model)
Sistemin beyni. Toplanan bilgileri kullanarak kullanıcıya anlamlı cevap üretir.
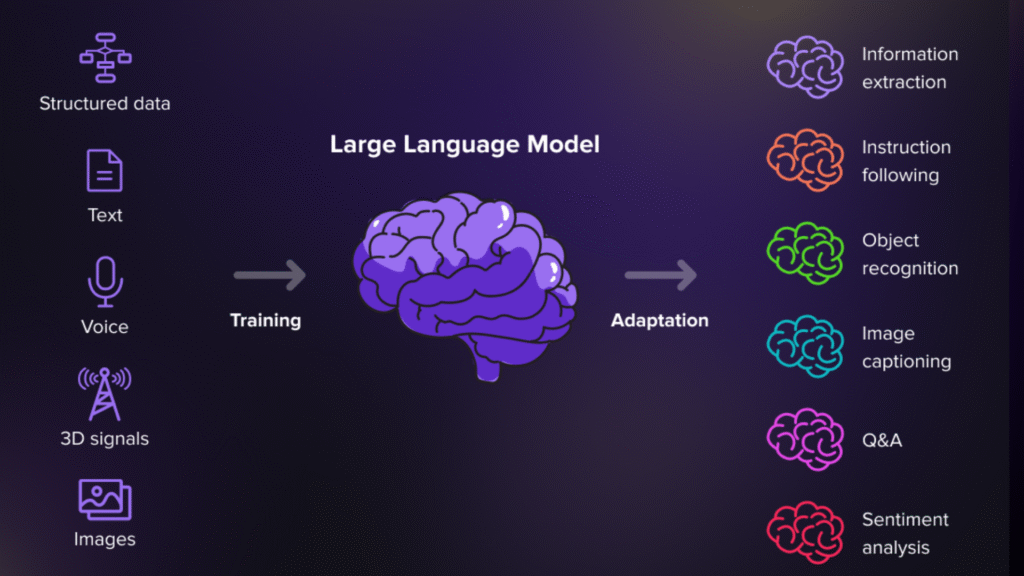
RAG’daki rolü:
Prompt şablonu:
"Aşağıdaki bilgileri kullanarak soruyu cevapla:
BAĞLAM:
{retriever'dan gelen bilgiler}
SORU: {kullanıcı sorusu}
CEVAP:"Örnek çalışma:
BAĞLAM:
"İade süresi 14 gündür. İade için fatura gereklidir.
Ürün kullanılmamış olmalıdır."
SORU: "Aldığım ayakkabıyı iade edebilir miyim?"
LLM CEVABI:
"Evet, ayakkabınızı iade edebilirsiniz. Bunun için:
- Satın alma tarihinden itibaren 14 gün içinde olmalısınız
- Faturanızı yanınızda getirmeniz gerekiyor
- Ayakkabı kullanılmamış ve orijinal kutusunda olmalıdır"Tüm Sistemin Birlikte Çalışması:
1. Kullanıcı sorar: "Kargo ücreti ne kadar?"
↓
2. Embedding: Soru vektöre çevrilir [0.3, 0.7, ...]
↓
3. Vektör DB: Benzer dokümanlar aranır
↓
4. Retriever: En alakalı 5 chunk getirilir
↓
5. Context Builder: Chunklar düzenlenir
↓
6. LLM: Bilgileri kullanarak cevap üretir
↓
7. Kullanıcıya döner: "Kargo ücreti 500 TL üzeri
alışverişlerde ücretsiz, altında 30 TL'dir."